Yeni modelim GemmaTR-WikiQA-4bit, Türkçe dilinde eğitilmiş 27 milyar parametreli bir yapay zeka modeli! Model, kişisel bilgisayarlarda kullanılabilmesi için 4-bit quantize edildi ve 16GB GPU'ya sahip bilgisayarlarda iyi performans sergiliyor. Normalde bu modeli kullanabilmek için 60GB GPU gereksinimi vardı, ancak 4-bit quantize edilmesi sayesinde bu gereksinim düşürüldü. Eğitim için ise en az 80GB GPU göz önünde bulundurulmalı.
Bu model, 1,937,069 Türkçe Vikipedi soru-cevap verisinden 1.7 epoch boyunca eğitildi ve gelişmeye devam ediyor. Aşağıdaki linklerden modelin detaylarına erişebilirsiniz:
https://huggingface.co/cenkersisman/GemmaTR-WikiQA-4bit-GGUF
https://ollama.com/cenker/GemmaTR-WikiQA-4bit
Ayrıca, Türkçe dilinde bilinen diğer açık kaynak modelleri de göz önünde bulundurursak:
YTU: ytu-ce-cosmos/Turkish-Llama-8b-Instruct-v0.1 – 8 milyar parametre
Boğaziçi Üniversitesi: boun-tabi-LMG/TURNA– 1.14 milyar parametre
Türkcell: TURKCELL/Turkcell-LLM-7b-v1 – 7 milyar parametre
Trendyol: Trendyol/Trendyol-LLM-7b-chat-v1.0 – 7 milyar parametre
Amacım GemmaTR-WikiQA-4bit ile Türkçe NLP dünyasına önemli bir katkı sağlamak! Devamı geliyor.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
https://huggingface.co/cenkersisman/gpt2-turkish-256-token
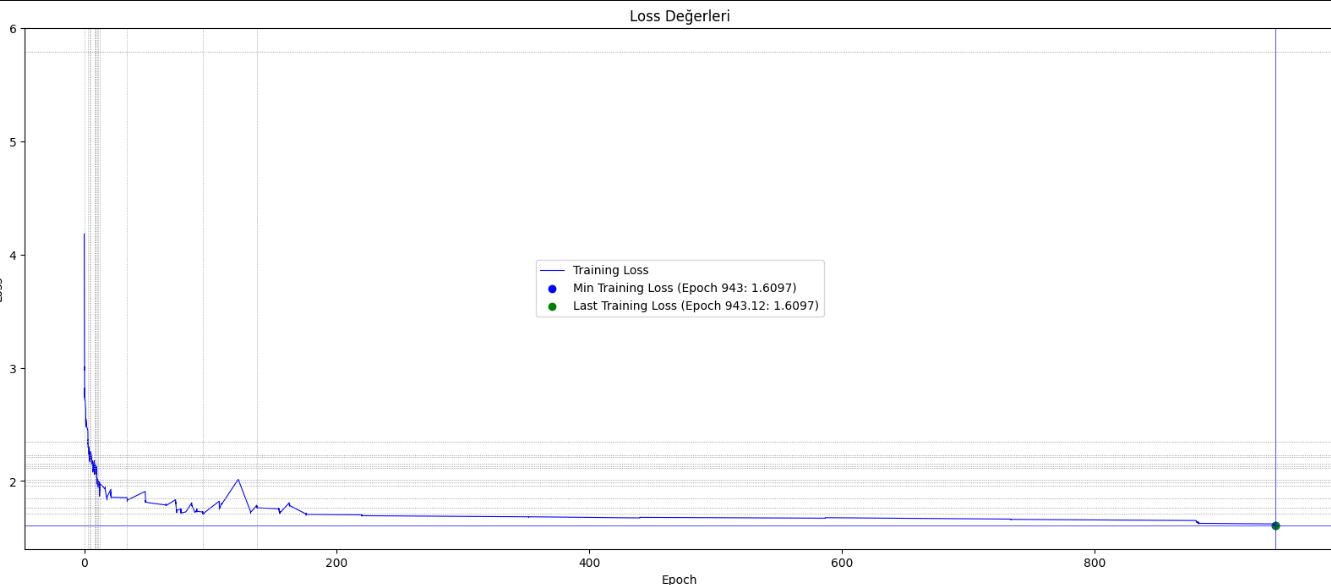
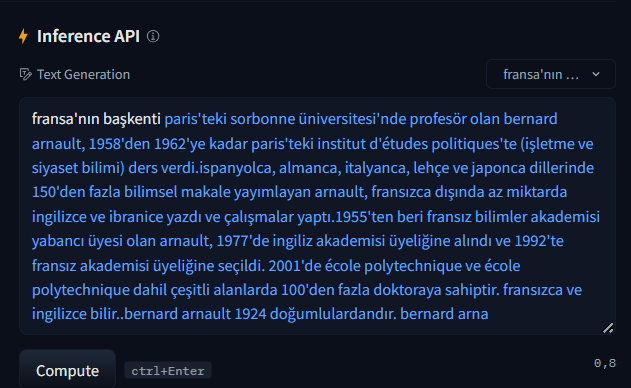
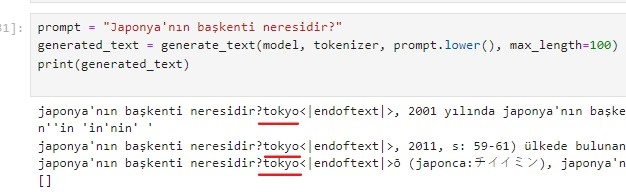
Aşağıdaki yazıyı bir ay önce yayınlamıştım. Şu anda kayıp değeri 1.68 den 1.60 seviyelerine düştü. Eğitim devam ediyor. Üretilen cevaplardaki düzelme artık hissedilmeye başladı. "Türkiye'nin en büyük şehirleri" ile başlayan cümle kur dediğimde eğitimin başlarında sadece birkaç şehir sayabilirken şimdi çok sayıda şehir sayabiliyor.
Önemli bir noktaya değinmek gerekirse: Bu sistem, tamamen sıfırdan başlayarak, mevcut imkanlarımla aylar süren bir çalışmanın sonucu olarak geliştirilmiş ve büyük firmaların kendi dil modellerine bağımsız bir alternatif olarak ortaya çıkmıştır. Türkçe yapısını öğrenmesi için Vikipedi sitesindeki tüm Türkçe cümleler gösterilip eğitilmiştir.
Önceki yazı:
Türkçe GPT-2 modeli eğitimi yaklaşık 1 senedir devam ediyor. Kayıp değeri son paylaşımdan beri 1.74 seviyesinden 1.68'e düştü. Artık daha uzun cümleler üretebiliyor. Bu modeli bir hamur gibi düşünün. İnce ayar ile eğitildikten sonra farklı amaçlara hizmet verebilir. İnce ayarla bu hamura şekil veriyorsunuz. Bu hamurdan ne ekmekler çıkar.

https://huggingface.co/cenkersisman/gpt2-turkish-256-token
Türkçe GPT-2 modeli eğitimi yaklaşık 1 senedir devam ediyor. Kayıp değeri son paylaşımdan beri 1.74 seviyesinden 1.68'e düştü. Artık daha uzun cümleler üretebiliyor. Bu modeli bir hamur gibi düşünün. İnce ayar ile eğitildikten sonra farklı amaçlara hizmet verebilir. İnce ayarla bu hamura şekil veriyorsunuz. Bu hamurdan ne ekmekler çıkar ne ekmekler!
Konu ile ilgili yazı: https://medium.com/@cenker/gpt-model-kullan%C4%B1larak-neler-yap%C4%B1labilir-b0569891922a
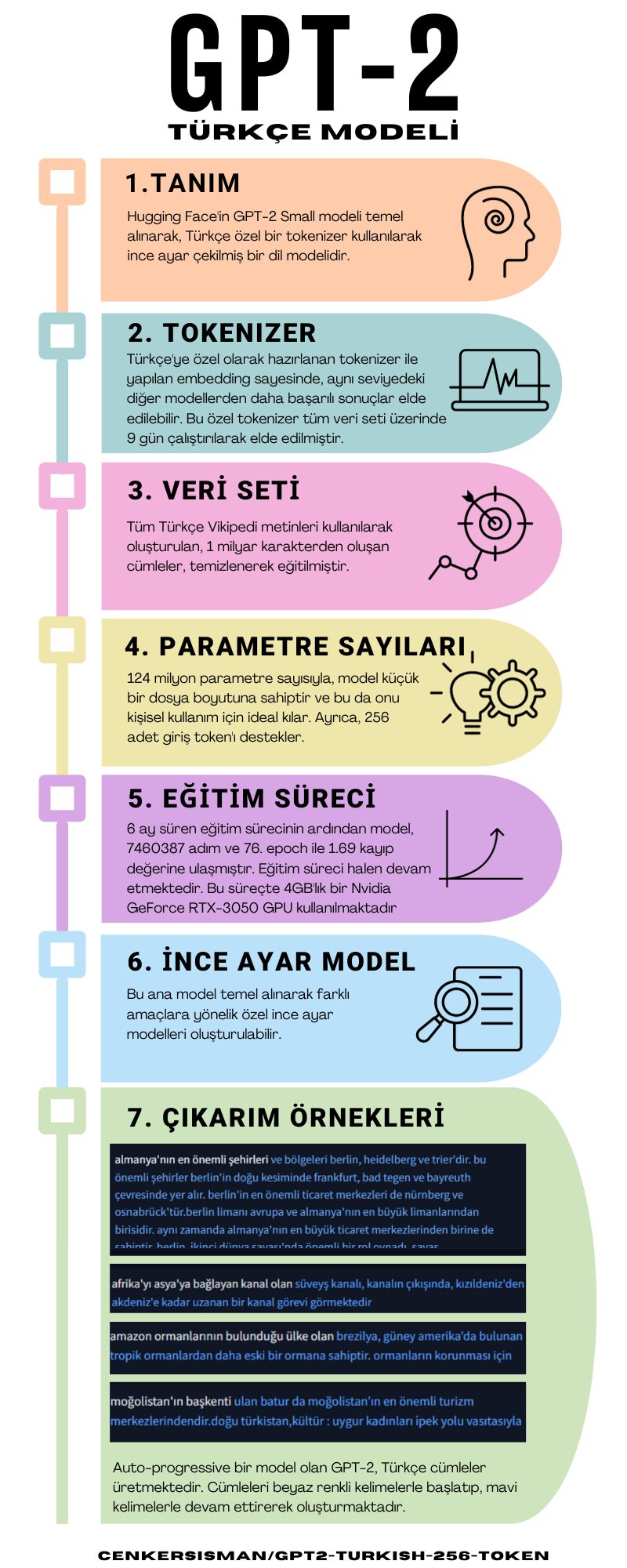
Türkçe GPT-2
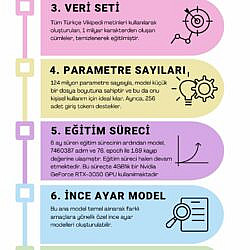
* Hugging Face'in GPT-2 Small modeli temel alınarak, Türkçe özel bir tokenizer kullanılarak ince ayar çekilmiş bir dil modelidir.
* Türkçe'ye özel olarak hazırlanan tokenizer ile yapılan embedding sayesinde, aynı seviyedeki diğer modellerden daha başarılı sonuçlar elde edilebilir. Bu özel tokenizer tüm veri seti üzerinde 9 gün çalıştırılarak elde edilmiştir.
* Tüm Türkçe Vikipedi metinleri kullanılarak oluşturulan, 1 milyar karakterden oluşan cümleler, temizlenerek eğitilmiştir.
* 124 milyon parametre sayısıyla, model küçük bir dosya boyutuna sahiptir ve bu da onu kişisel kullanım için ideal kılar. Ayrıca, 256 adet giriş token'ı destekler.
* 6 ay süren eğitim sürecinin ardından model, 7460387 adım ve 76. epoch ile 1.69 kayıp değerine ulaşmıştır. Eğitim süreci halen devam etmektedir. Bu süreçte 4GB'lık bir Nvidia GeForce RTX-3050 GPU kullanılmaktadır
* Bu ana model temel alınarak farklı amaçlara yönelik özel ince ayar modelleri oluşturulabilir.
* Auto-progressive bir model olan GPT-2, Türkçe cümleler üretmektedir. Cümleleri beyaz renkli kelimelerle başlatıp, mavi kelimelerle devam ettirerek oluşturmaktadır.
https://huggingface.co/cenkersisman/gpt2-turkish-256-token #gpt #gpt2 #llm #türkçegpt #ceydasistan

https://huggingface.co/cenkersisman/gpt2-turkish-128-token
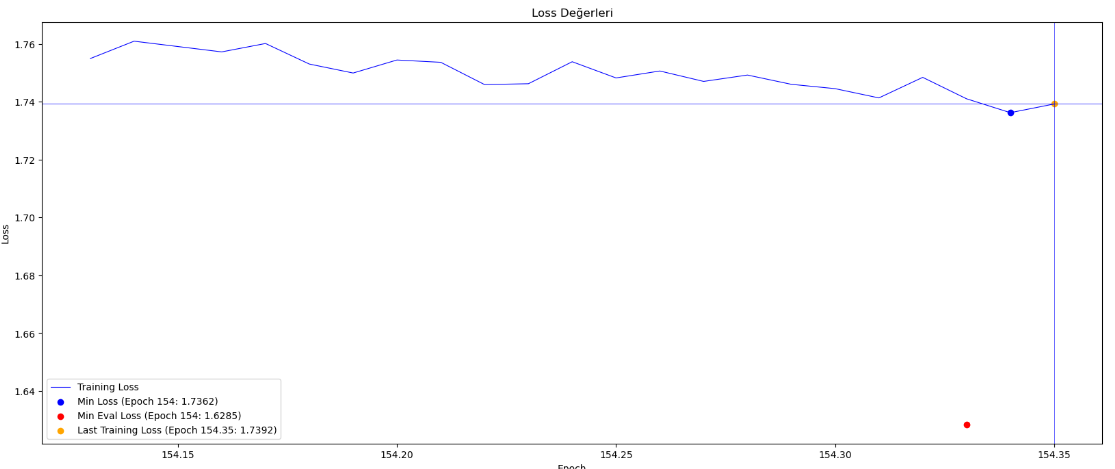
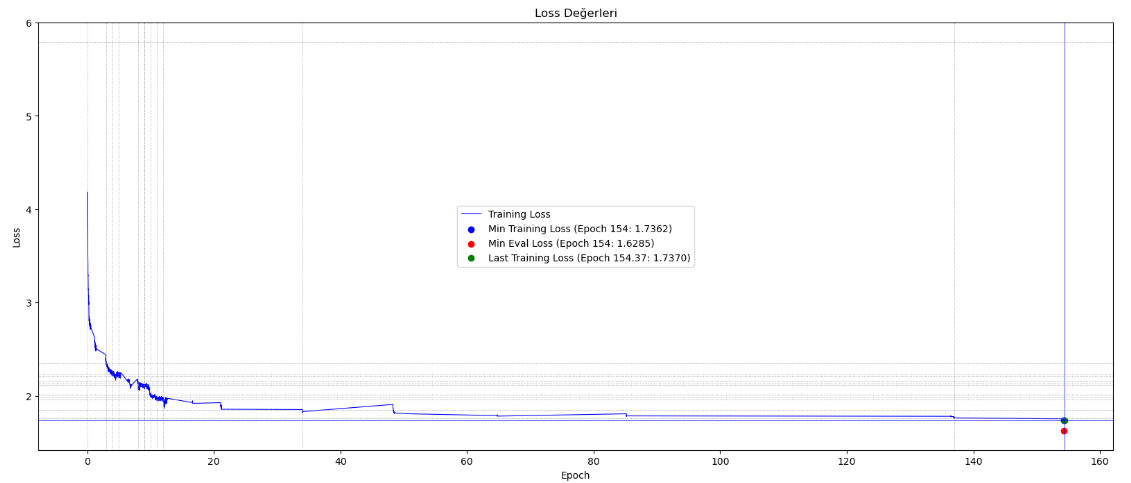
Türkçe GPT2, 154. epoch da eğitilmeye devam ediyor. kayıp (loss) değeri düştükçe, halüsinasyon olmasına rağmen önceki halinden daha düzgün cevaplar oluşturabildiği hissediliyor. Eğitimine 6 ay önce başlamıştım ve aralıksız olarak sürekli gelişme gösteriyor. Şu anda paylaşımlı hafıza desteği ile beraber 20GB GPU ile eğitiliyor. Detaylar linktedir. Geliştiriciler kendi dil modellerinde veya projelerinde kullanabilir.
CEYD-A'nın bugüne özel açılış sayfası! Cumhuriyet Bayramımız'ın 100. yılı kutlu olsun. 🇹🇷
#CumhuriyetBayramı #100yıllıkgurur #cumhuriyet #29EkimCumhuriyetBayramı
#Cumhuriyet100Yaşında
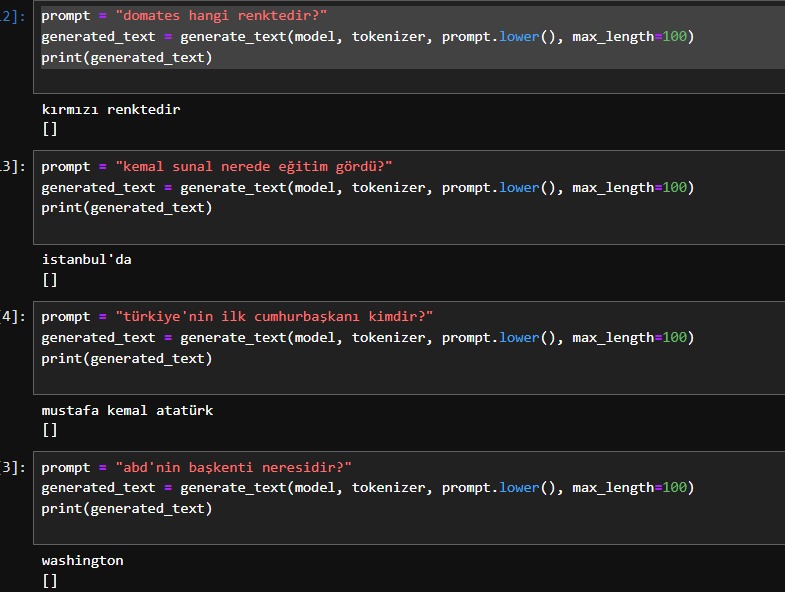
Hatırlarsanız Türkçe GPT2 modeli hazırlıyorum. Bu çalışmaya başlamamın nedenlerinden biri, öncesinde Vikipedi metinlerinden soru ve cevap üretebilen başka bir model üzerinde çalışmamdı aslında. Üretilen soru ve cevaplara uyumlu kaynağın GPT modelini önceden oluşturabilirsem farklı sorulara daha uyumlu cevaplar verebileceğini planlıyordum. O yüzden GPT modelini eğitmeye başlamıştım 3 ay önce. Yanılmamışım. Yolum uzun olduğu için bir an evvel nasıl sonuçlar ile karşılacağımın denemelerini yaptım. Vikipedi'den oluşturduğum sadece 5000 soru cevabı, benim model üzerinde eğitmem, umut verici cevaplar almaya yetti. Aşağıda çok farklı konularda rastgele sorduğum sorulardan bir kaçı. Başlangıçta milyonlarca soru ve cevap üretip bunları nasıl eğiteceğim diye kara kara düşünürken, şimdi çalışmaların insana nasıl farklı kapılar açtığını görüyorum. Şimdi tünelin sonundaki ışık gözüktü. #chatgpt #gpt2 #gpt #ceydasistan
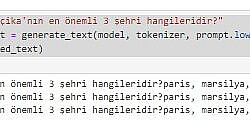
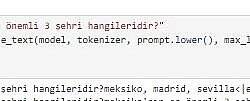
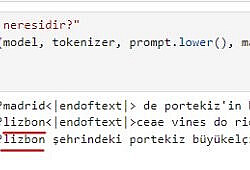
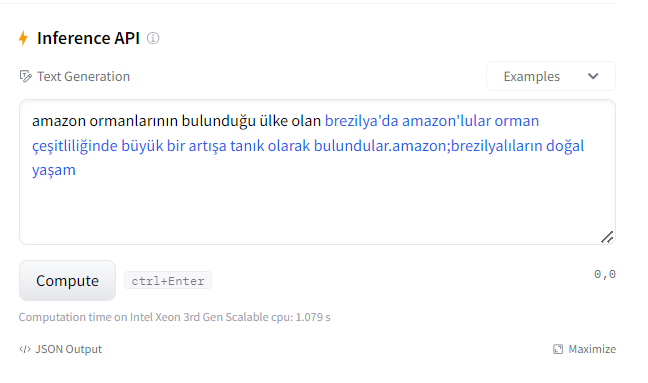
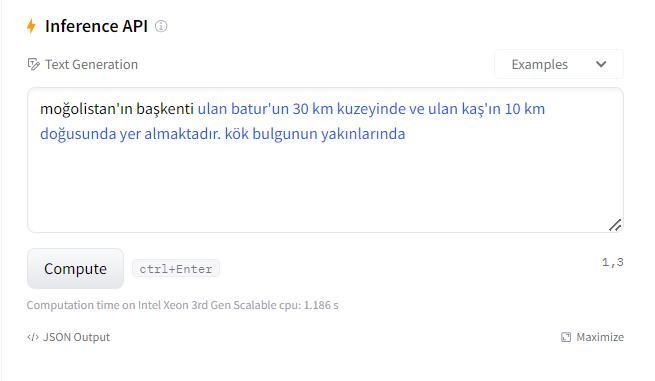
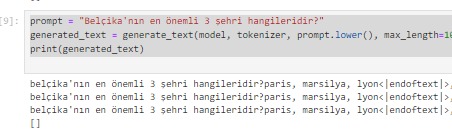
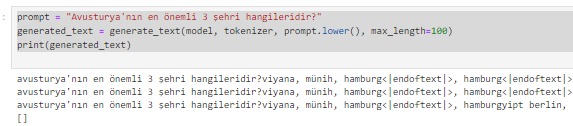
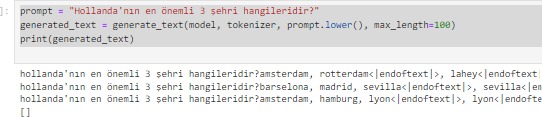
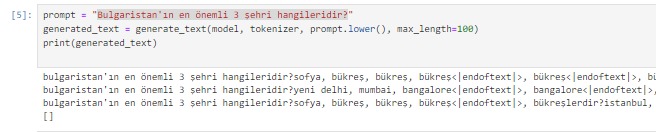
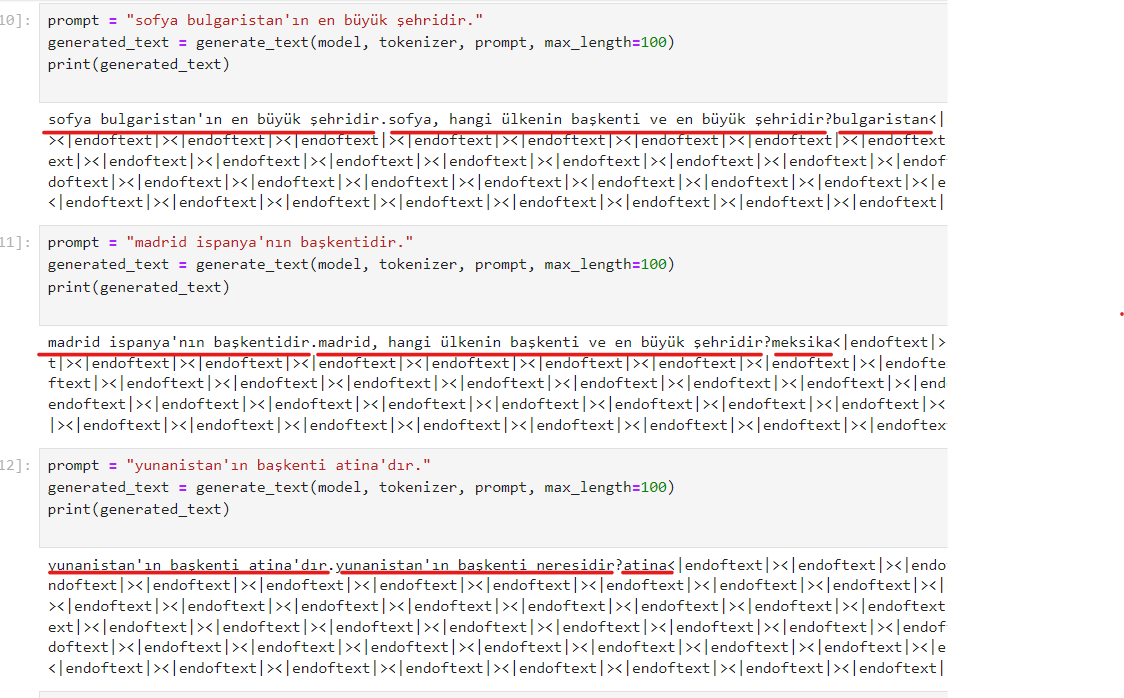
Vikipedi metinlerinden hazırladığım hala eğitiminin devam ettiği GPT2 modelinin ne kadar öğrendiğini gözlemlemek için bir çalışma yaptım: Ona birkaç ülkenin en önemli 3 şehrini söyledim (sondaki görsel) ve ondan farklı ülkelerin 3 şehrinin ne olabileceğini tahmin etmesini istedim.
Sonuçlar aşağıda: Başta sonuçların hatalı olduğunu düşünebilirsiniz. Ama aslında öğrenmiş. Eğitimin 20.evresinde olduğu için bilmediği konularda bile öğrendiği kadarını yorumladığını farkettim. Dikkat ederseniz şu ana kadar tam eğitilebildiği kadarını doğru doldurabiliyor. Kalan kısımları kültürel benzer ve yakın ülkenin şehirleri ile dolduruyor. Mesela Pakistan ile Hindistan'ı aynı sanıyor. Almanca dillerini konuşan Avusturya ile Almanya'yı, Fransızca konuşan Belçika ile Fransa'yı aynı yere koyuyor. İspanyolca konuşan Meksika ve İspanya'yı da benzer düşünüyor.. Amaç olan 100. evreye yaklaşınca nasıl bir eğitime uğrayacağını merak ediyorum.
Modelin son haline ulaşmak için: (Kullanımı ücretsizdir)
https://huggingface.co/cenkersisman/gpt2-turkish-900m
Model Açıklaması
GPT-2 Türkçe Modeli, Türkçe diline özelleştirilmiş olan GPT-2 mimarisi temel alınarak oluşturulmuş bir dil modelidir. Belirli bir başlangıç metni temel alarak insana benzer metinler üretme yeteneğine sahiptir ve geniş bir Türkçe metin veri kümesi üzerinde eğitilmiştir. Modelin eğitimi için 900 milyon karakterli Vikipedi seti kullanılmıştır. Eğitim setindeki cümleler maksimum 48 tokendan (token = kelime kökü ve ekleri) oluşmuştur bu yüzden oluşturacağı cümlelerin boyu sınırlıdır.. Türkçe heceleme yapısına uygun tokenizer kullanılmış ve model 7.5 milyon adımda yaklaşık 12 epoch eğitilmiştir. Eğitim halen devam etmektedir. Eğitim için 4GB hafızası olan Nvidia Geforce RTX 3050 GPU kullanılmaktadır.
#ceydasistan #gpt #gpt2 #chatgpt
Kişisel çabalarımla, Türkçe'ye özel, bizim için, bir GPT-2 modeli oluşturmayı deniyorum. Bu amaçla, Türkçe cümle yapısına özgü bir Tokenizer'ı 9 gün boyunca sürekli çalıştırarak oluşturdum ve bu model hala bu Tokenizer'ı kullanarak eğitilmeye devam ediyor. 900 milyon karakterden oluşan ve 10 milyon cümleyi içeren Türkçe Vikipedi metinleri, bu modelin eğitiminde kullanılıyor. Model eğitiminde şu an 32.gündeyim.
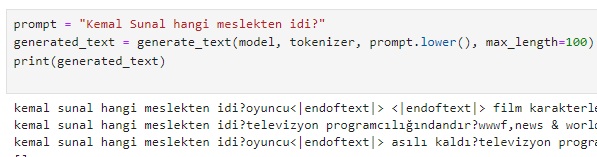
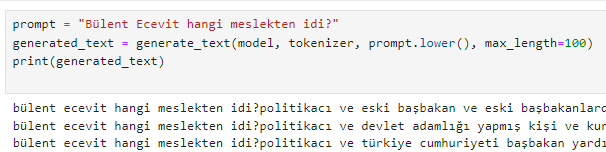
Eğitilirken kayıp değeri her geçen gün azalıyor ve aşamalı temizlemelerle daha iyi performans elde ediliyor. Başarıyı ölçmek için yaptığım bir çalışmada, modele birkaç yeni soru-cevap örneği ekleyerek ince ayar yaptım. Yani, modele bu tip sorulara nasıl cevap vermesi gerektiğini öğrettim. Ardından, modele bu tip sorulara benzeyen farklı soruları yanıtlamasını da istedim.
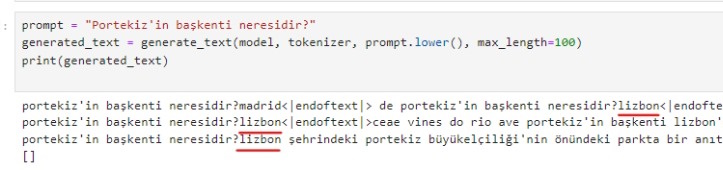
İlk denemede, 8 farklı ülkenin başkentini kendim söyledim. Sonra başka bir ülkenin başkentini sordum ve eğer model gerçek cevabı doğru bir şekilde verebiliyorsa, bu modelin başarılı olduğunu söyleyebiliriz. Ana modelin eğitimi sırasında kayıp değerleri 0'a yaklaştıkça ve aşırı doyma olmadıkça daha iyi performans bekliyorum.
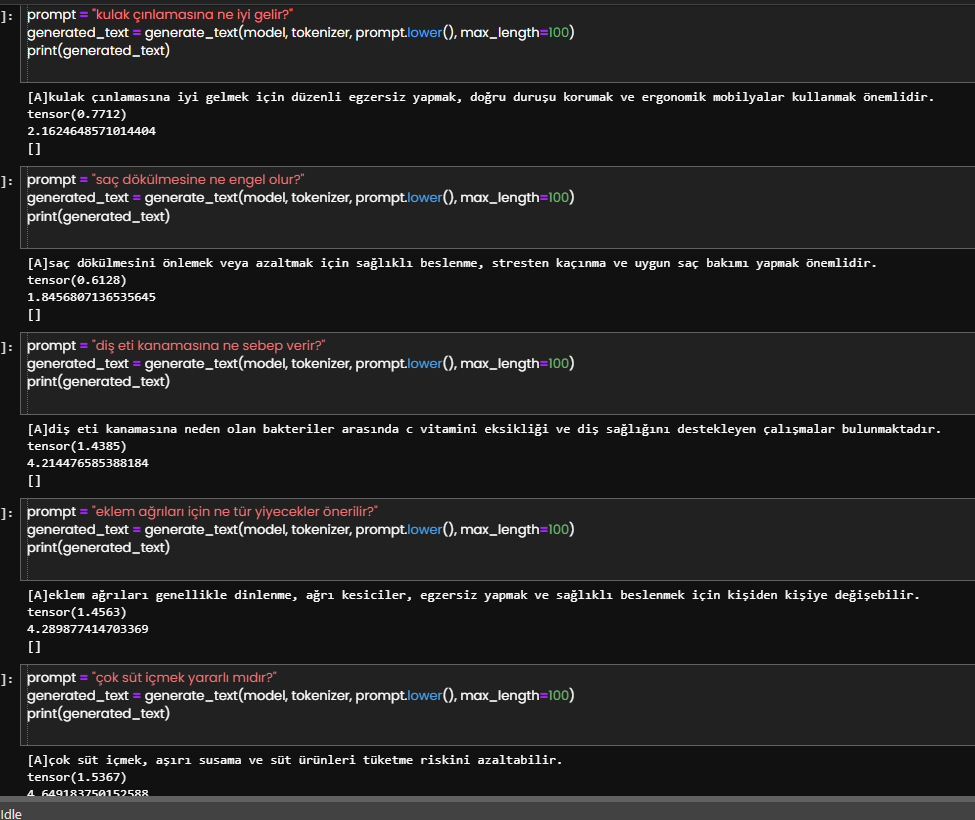
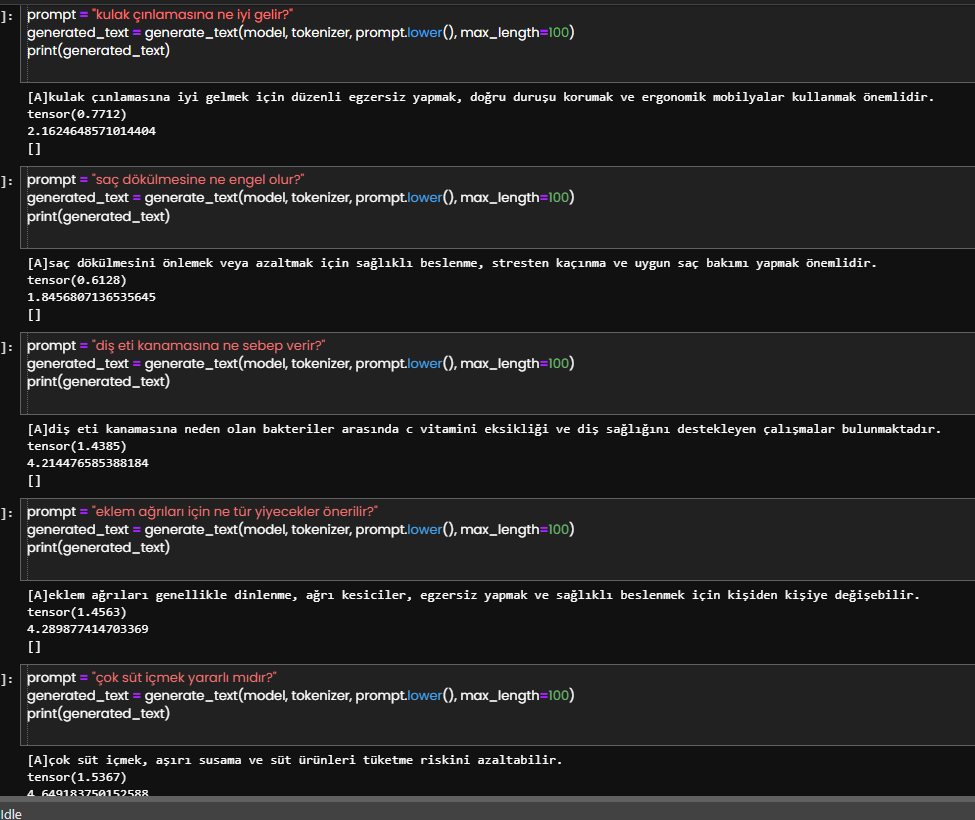
İlk görsellerde, modele verdiğim örnekler bulunuyor. Sonraki görsellerde ise modelden almak istediğim soruların cevapları yer alıyor.
Özetle, sonucu kendisi eğitilmiş modelden öğrenip bilgiyi çekebildiğini gözlemledim.
Basit bir anlatımla Almanya'nın başkenti Berlin ise Fransa'nın başkenti nedir? sorusuna modelden doğru cevabı alabilmek. İlişkileri doğru anlamış mı sorgulayabilmek. "Almanya'nın Berlin ile nasıl bir ilişkisi var ise Fransa'nın ilişkisinin karşılığı nedir sorusuna cevap alabilmek. Modelin kavramları öğrenip öğrenmediğini gözlemleyebilmek.
Geliştiriciler için modelin son hali:
https://huggingface.co/cenkersisman/gpt2-turkish-900m
GPT-2 Türkçe Modeli, Türkçe diline özelleştirilmiş olan GPT-2 mimarisi temel alınarak oluşturulmuş bir dil modelidir. Belirli bir başlangıç metni temel alarak insana benzer metinler üretme yeteneğine sahiptir ve geniş bir Türkçe metin veri kümesi üzerinde eğitilmiştir. Modelin eğitimi için 900 milyon karakterli Vikipedi seti kullanılmıştır. Eğitim setindeki cümleler maksimum 48 tokendan (token = kelime kökü ve ekleri) oluşmuştur bu yüzden oluşturacağı cümlelerin boyu sınırlıdır.. Türkçe heceleme yapısına uygun tokenizer kullanılmış ve model 7.5 milyon adımda yaklaşık 12 epoch eğitilmiştir. Eğitim halen devam etmektedir. Eğitim için 4GB hafızası olan Nvidia Geforce RTX 3050 GPU kullanılmaktadır.

"Türkçe GPT modeli şu an eğitim aşamasında! Geliştiriciler, Hugging Face web sitesinde paylaşılan bu özel Türkçe modelini kullanabilecekler. Bu model, yaklaşık 900 milyon karakterden oluşan ve yaklaşık 10 milyon cümle içeren bir veri setiyle eğitildi. Türkçe için özel olarak hazırlanan bir belirteçleyici (tokenizer) kullanıldı ve tüm Vikipedi metinleri kelime kökleri ve ekleri açısından detaylı bir işlemden geçirilerek oluşturuldu. Bu işlem, çalıştırılması 9 gün süren bir uygulama tarafından gerçekleştirildi.
Eğitim devam etmektedir. 2 günde yaklaşık 1.5 Epoch tamamlanmaktadır
Türkçe dilinde yapay zeka çalışmalarına yeni bir boyut kazandırmak için sabırsızlanıyorum!"
https://huggingface.co/cenkersisman/gpt2-turkish-900m?text=limon
Kullanılan makine özellikleri:
Intel Core i7 11800H 32GB + NVidia Geforce RTX 3050 4GB GPU
#chatgpt #gpt #turkcegpt #ceydasistan
We’re on a journey to advance and democratize artificial intelligence through open source and open science.

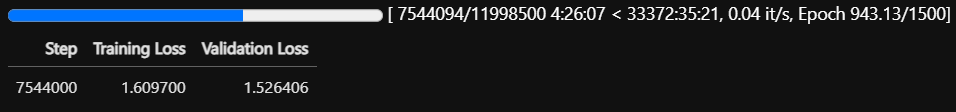























Başarılarınızı uzaktan takip eden birisi olarak, tebrik ediyorum, cahilce soruyorum, sizin ceyda vardı, bu onun yerine mi geliyor yani ceydanın yapay zekası bu model mi olacak, oldu? Konumlandırmaları nasıl?
Estağfurullah, teşekkür ederim. CEYD-A sadece bir sesli asistan değil geliştirilebilir sesli asistandı. Yani kullanıcılar da geliştirebilir düzeye geldi ve onu kendiliğine bıraktım diyebiliriz. Şu anda isteyen kullanıcılar ChatGPT veya farklı modellerin API larına bağlanan CEYD dili ile kod yazıp CEYD-A ya entegre edebilirler. Hatta bu ve bunun gibi localdeki modellere bağlanıp sesli bir asistan hale getirilebilir.
Hazır kodları CEYD-A kurulu Android telefondan girip linklerin üzerine tıklayarak aktif hale getirebilirsiniz.
https://ceyd-a.com/ceydcodes.html
Veya
kodla.ceyd-a.com sitesinden kendi kodlarınızı geliştirebilirsiniz.
https://web.ceyd-a.com/2023/01/ceyd-a-ya-gpt-veya-farkli-bir-sistem-entegre-etmek/
https://web.ceyd-a.com/2023/01/ceyd-a-proxy-ile-islerinizi-bilgisayariniza-yaptirin/
Hocam neden Gemma'yı tercih ettiniz merak ettim ? Gemmanın avantaj/ları nelerdir? Mistral ve Llama daha iyi gibi geliyor standart bir kullanıcı olarak.
Türkçe akıl yürütme için Gemma2 yi daha iyi buldum açıkçası. Ayrıca performans parametre boyutları ile de etkileniyor. 27B lik bir model 8B veya 9B lik bir modelden daha başarılı oluyor genelde. llamanın 70b parametreli versiyonu gerçekten çok iyi. Eğer soru ve cevaplarınızı küçük contextlerde kullanıyorsanız llama3.1 8b işinizi görür hatta küçük işlerde ben de onu tercih ediyorum. Ama eğer çok sayıda işlemi aynı anda sorgulatıp (10 veya üstü) işlemlerin sonuçlarından bir yere ulaşmasını istiyorsanız ve daha az halüsinasyona sahip bir model istiyorsanız 27B işinizi görecektir. Eğer llama nın 35b veya benzer parametre boyutlarında versiyonları olsaydı onu tercih edebilirdim. Sadece parametre değil başka faktörlerde var aslında mesela aya nın 35b lik modeli var ama ne yazık ki tatmin etmedi testlerimde.
Hocam son 2 yılda chatgpt gelişi ve diğer modellerin de birden çıkışı ceyda'yı etkiledi mi? Ben hatırlıyorum buradan paylaştıklarınızla yıllardır kendiniz bir model eğittiniz yükselttiniz. Şimdi bir firma gelip -örnek veriyorum- sizin modelinizden milyon kat daha fazla eğitilmiş model çıkardı.
Not: bu sorum ceyda üzerinde değil, genel olarak bu işi yapanlar için.
Merhaba, CEYD-A diğer rakiplerinde farklı bir sesli asistan olduğu için etkisi az oldu aslında. Çünkü CEYD-A açılımına da bakarsanız CEYD dili ile geliştirilen Asistan. Kendi açık kaynak oluşturabileceğiniz geliştirme dili var ve sadece kendi entegre modeli değil farklı modelleri de kendi bünyesine ekleyebiliyorsunuz. Kullanıcı bunu yapabiliyor. Bir geliştirme ortamı var sonuçta cepten webten geliştirebiliyorsunuz. Örneğin ChatGPT yi veya farklı modelleri entegre etmek için CEYD kodlarına aşağıdan ulaşabilirsiniz.
https://ceyd-a.com/ceydcodes.html
Ama genel olarak diğer sesli asistanları da söylüyorsanız evet muhakkak etkilendiler.
@cenker-sisman hocam şu anda da istersek ceyd dili ile bir şeyler yapabiliyor muyuz? Hala aktif mi İnceleyim bir. Çalışmalarınızı severek rakip ediyorum saygılar.
@deniz-fidan Merhaba Deniz bey, evet https://kodla.ceyd-a.com sitesinden kendi kodlarınızı girebilirsiniz. Kullanıcı isminiz ile sonra mobil uygulamadan giriş yaptığınızda kendi kodlarınızı CEYD-A üzerinde kullanabilirsiniz.
https://web.ceyd-a.com/list/all-posts/
sayfasından da yardımcı olabilecek yazılara da ulaşabilirsiniz.
Bir sorun olursa bana https://web.ceyd-a.com/bize-ulasin/ sayfasından da ulaşabilirsiniz..
@cenker-sisman çok teşekkürler 🫡🫡
Çalışmayı ayrı tutarak (tebrikler), bu işin maliyeti gene son kullanıcıya kaymağı ise 3 büyük sistem üreticisine ve donanımcılarına kalacak gibi duruyor ve daha da kötüsü kimse son kullanıcıya sormuyor, "gerçekten istiyor musun?" diye.
"AI cpu'yu satın almak istemiyorum, neden boğazımdan aşağı iteliyorsun?" mesela...