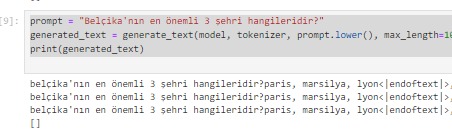
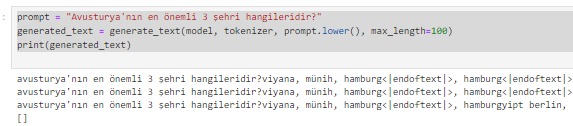
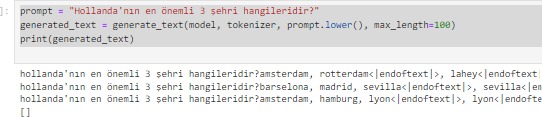
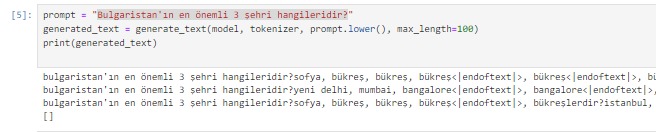
Vikipedi metinlerinden hazırladığım hala eğitiminin devam ettiği GPT2 modelinin ne kadar öğrendiğini gözlemlemek için bir çalışma yaptım: Ona birkaç ülkenin en önemli 3 şehrini söyledim (sondaki görsel) ve ondan farklı ülkelerin 3 şehrinin ne olabileceğini tahmin etmesini istedim.
Sonuçlar aşağıda: Başta sonuçların hatalı olduğunu düşünebilirsiniz. Ama aslında öğrenmiş. Eğitimin 20.evresinde olduğu için bilmediği konularda bile öğrendiği kadarını yorumladığını farkettim. Dikkat ederseniz şu ana kadar tam eğitilebildiği kadarını doğru doldurabiliyor. Kalan kısımları kültürel benzer ve yakın ülkenin şehirleri ile dolduruyor. Mesela Pakistan ile Hindistan'ı aynı sanıyor. Almanca dillerini konuşan Avusturya ile Almanya'yı, Fransızca konuşan Belçika ile Fransa'yı aynı yere koyuyor. İspanyolca konuşan Meksika ve İspanya'yı da benzer düşünüyor.. Amaç olan 100. evreye yaklaşınca nasıl bir eğitime uğrayacağını merak ediyorum.
Modelin son haline ulaşmak için: (Kullanımı ücretsizdir)
https://huggingface.co/cenkersisman/gpt2-turkish-900m
Model Açıklaması
GPT-2 Türkçe Modeli, Türkçe diline özelleştirilmiş olan GPT-2 mimarisi temel alınarak oluşturulmuş bir dil modelidir. Belirli bir başlangıç metni temel alarak insana benzer metinler üretme yeteneğine sahiptir ve geniş bir Türkçe metin veri kümesi üzerinde eğitilmiştir. Modelin eğitimi için 900 milyon karakterli Vikipedi seti kullanılmıştır. Eğitim setindeki cümleler maksimum 48 tokendan (token = kelime kökü ve ekleri) oluşmuştur bu yüzden oluşturacağı cümlelerin boyu sınırlıdır.. Türkçe heceleme yapısına uygun tokenizer kullanılmış ve model 7.5 milyon adımda yaklaşık 12 epoch eğitilmiştir. Eğitim halen devam etmektedir. Eğitim için 4GB hafızası olan Nvidia Geforce RTX 3050 GPU kullanılmaktadır.
#ceydasistan #gpt #gpt2 #chatgpt














Hocam sizin bu projeden kazancınız ne oluyor? Maddi olarak sürdürebiliyor musunuz?
merhaba yapay zeka benim çocukluk yaşlarımdan beri ilgi alanım ve geliştirdiklerimi hobi olarak severek geliştiriyorum. Ne yazık ki maddi olarak bir kazanç getirmiyorlar. Ancak maddi bir destek olsaydı kesin daha hızlı geliştirmeler sağlayabilirdim. Elimdeki kişisel notebook sayesinde onu en verimli kullanarak geliştirmelere devam ediyorum.
@cenker-sisman Tübitak vs. gibi bir yerlerden destek almayı düşündünüz mü?
@leventp @cenker-sisman Levent abiyle yapay zeka konusunda bir yayın yapsanız ne güzel olurdu...
Bu yazıda kullandığım ve eğitime devam ettiğim model 48 token destekli bir model. Şu anda başka bir makinede 128 token lı daha gelişmiş bir model eğitiyorum. 48 token yaklaşık 48 kelime/hece lik cümleler kurabilmesi demek. 128 tokenlık model ile yaklaşık 3 kat daha uzun cümleleri işleyip üretebilmesini sağlayabileceğiz.
https://huggingface.co/cenkersisman/gpt2-turkish-128-token