https://huggingface.co/cenkersisman/gpt2-turkish-256-token
Aşağıdaki yazıyı bir ay önce yayınlamıştım. Şu anda kayıp değeri 1.68 den 1.60 seviyelerine düştü. Eğitim devam ediyor. Üretilen cevaplardaki düzelme artık hissedilmeye başladı. "Türkiye'nin en büyük şehirleri" ile başlayan cümle kur dediğimde eğitimin başlarında sadece birkaç şehir sayabilirken şimdi çok sayıda şehir sayabiliyor.
Önemli bir noktaya değinmek gerekirse: Bu sistem, tamamen sıfırdan başlayarak, mevcut imkanlarımla aylar süren bir çalışmanın sonucu olarak geliştirilmiş ve büyük firmaların kendi dil modellerine bağımsız bir alternatif olarak ortaya çıkmıştır. Türkçe yapısını öğrenmesi için Vikipedi sitesindeki tüm Türkçe cümleler gösterilip eğitilmiştir.
Önceki yazı:
Türkçe GPT-2 modeli eğitimi yaklaşık 1 senedir devam ediyor. Kayıp değeri son paylaşımdan beri 1.74 seviyesinden 1.68'e düştü. Artık daha uzun cümleler üretebiliyor. Bu modeli bir hamur gibi düşünün. İnce ayar ile eğitildikten sonra farklı amaçlara hizmet verebilir. İnce ayarla bu hamura şekil veriyorsunuz. Bu hamurdan ne ekmekler çıkar.
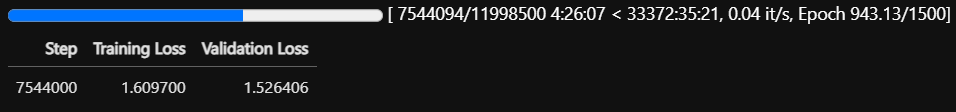

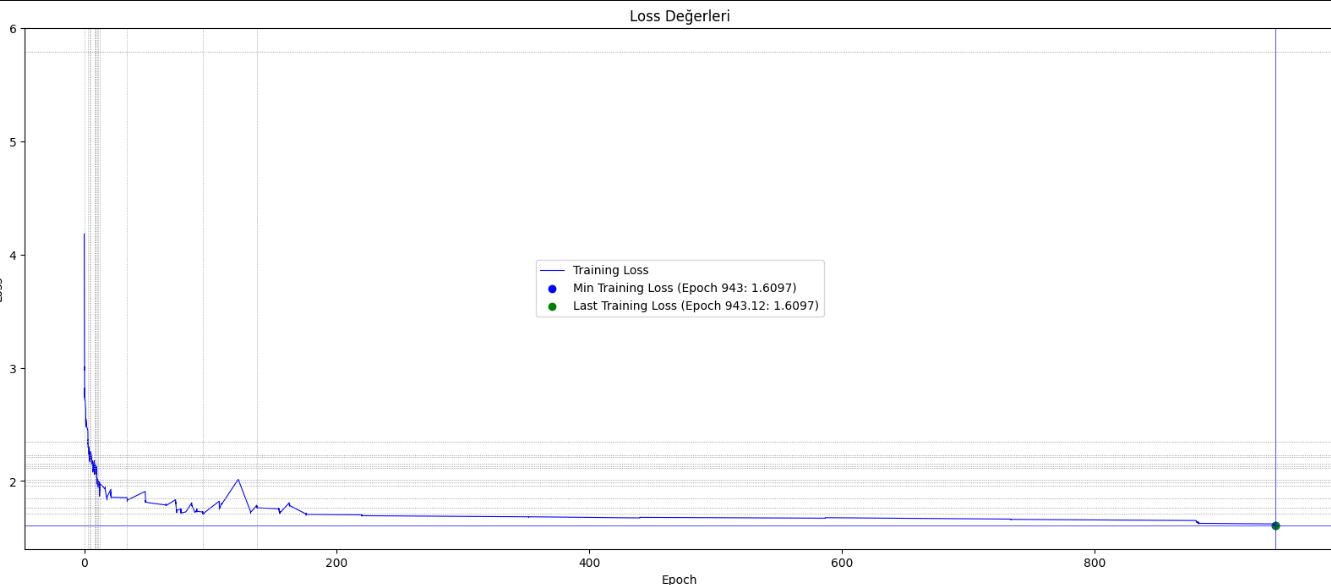










200 epochtan önceki eğitimlerde net düşüş varken 200 epochtan sonra loss dramatik olarak azalmıyor, modelin başarısı bu sırada çok artıyor mu?
Tokenization'ı nasıl yaptınız?
Merhaba evet artık dramatik azalma yok ama kullandığım makinede yeterli hafıza olsa idi daha da olumlu anlamda düşerdi. Tokenizer i Türkçe'ye özgü hazırladığım bir tokenizer o yüzden Türkçe cümlelerde daha başarılı sonuçlar görebiliriz.
Modelin başarısı her loss düşüşünde kendini az az belli ediyor. 1.70 den 1.60 a düştüğünde halüsinasyonlar daha da azaldı.
Hala halüsinasyon var ama cümle yapılarını ilk halinden daha iyi anlamış. Kelimelerin anlamlarını kavramlarını daha iyi oluşturmuş. Bu modeli cümle oluşturucu olarak düşünün. Asıl bundan sonra üzerinde ince ayar modeller geliştiğinde sonuçları göreceksiniz.
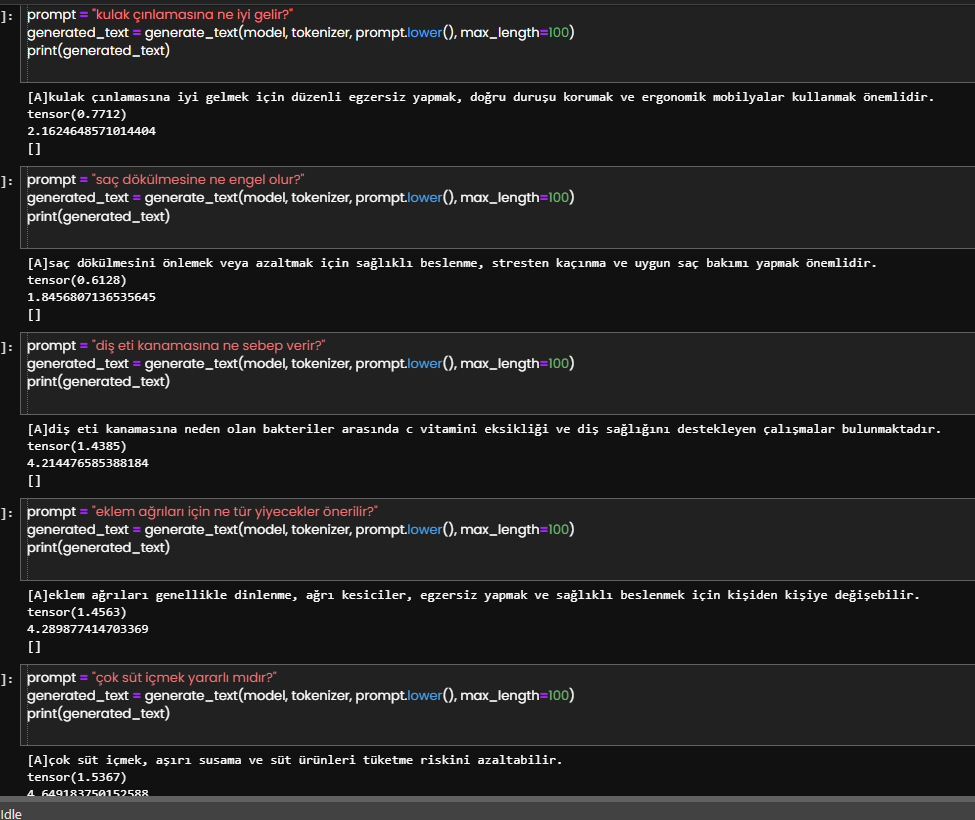
İnce ayar yapılmış bir model örneği. Türkçe GPT modeline birkaç soru cevap örneği verip tekrar hızlıca eğitiyorsunuz. Sonrasında aşağıdaki gibi ona eğitmediğiniz örnek soruları sorunca size cevap verebiliyor. Hala halüsinasyon ve ara sıra saçmalama var ancak günden güne iyileşiyor sistem.
Cevaplarında verdiği bazı yorumlara dikkat edin. Onlar bu ana modelde öğrendiği cümle yapılarından oluşuyor. İnce ayar modellerinde ise konu ile ilgili detayları gösterebiliyorsunuz. Kendisi öğrendiği Türkçe yapısına göre yorum katıyor.
@cenker-sisman Hocam bir şey sorucam. Bu eğitilebilen xxxx GPT'ler neden Chatgpt'den sonra çoğaldı da herkes kendi GPT'sini yapmaya başladı? Yani demek istediğim ChatGPT'den önce bunu niye kimse yapmadı, yapamadı mı, düşünemedi mi?
Niye şuan bir ton GPT hayatımıza girdi yani özetle soru bu. Merakımdan soruyorum yanlış anlaşılmasın.
ChatGPT den önceki yakın zamanda da GPT ler vardı ama veri, parametre boyları daha azdı. Örneğin benim kendi modelim GPT2 ayarında sadece 128 milyon parametresi var. bu parametrelerin tıplı insan beynindeki nöronlar gibi birbirleriyle etkileşmesiyle cevap verebiliyor. GPT3 de imkanlar zorlandı veri ve parametre sayısı normal bir bilgisayarın işlemesinin çok çok üstündeydi. Sadece dünyanın en büyük firmalarının finanse edebileceği bir boyuta geldi. Facebook Nvidia dan 500 bin adet GPU satın aldı. Bu muazzam bir rakam.. Bu GPU ları aynı anda çalıştırıp benim senelerce hatta onlarca sene yapabileceğim eğitimi bu makineler şu an gerçekleştiriyorlar. ChatGPT (GPT v3.5 ile) bir kapı açtı bakın paran varsa donanım varsa bu algoritma bu işi çözüyor dedi diğer tüm büyük firmalar da başladılar işe.
Not: Ben sadece tek bir GPU ile eğitim yapıyorum 🙂
@cenkersisman Anladım hocam açıklama için teşekkür ederim. Bu arada seo için türkçe makale yazan falan kelime başına ücret biçilerek kendi hizmetini satanlar falan var. O tarz hizmetler direk gpt-4 üzerinden çalışıyor değil mi yoksa bir özelleştirme var mı?
Evet şu anda bu pazarın en büyük yükünü OpenAI GPT4 üstleniyor. Google Gemini 1.5 ile, Facebook LLAMA2 ile , Mistral vs.. Bu modellere LLM (Large Language Model) deniyor. Son kullanıcı makinesinde hatta orta ölçekli firmaların kendi sunucularında barındırılamayacak ve işlenemeyecek kadar büyük modeller. O yüzden ne yazık ki bu hizmetlere kişisel verilerinizi yazılarınızı da sağlayarak hizmet alıyorsunuz. Eğer makineniz çok güçlü bir GPU ya sahip ise örneğin RTX4090 gibi ancak ince ayar çekebilirsiniz lokaldeki modellere.