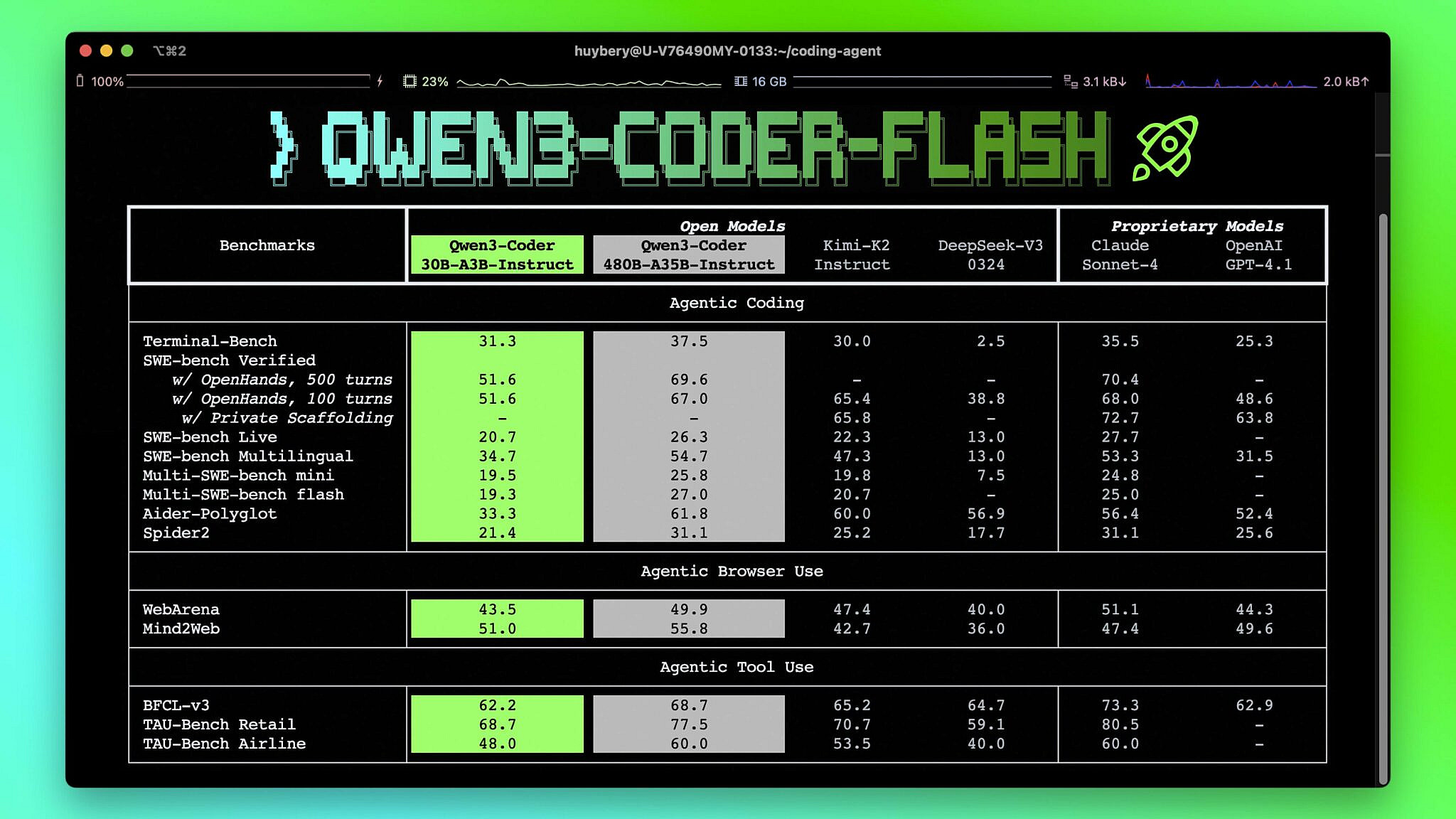
Local AI'ların da kodlama başarısı fena değilmiş. SWE Bench'te Claude %70 başarı alırken Qwen3-Coder 30B %51 almış. (Qwen3-Coder 480B'yi bir kenara bırakıyorum. Claude gibi o da %69 başarı almış ancak son kullanıcının ulaşamayacağı minimum 240GB boyutunda VRAM istiyor.)
Qwen3-Coder 30B ise minimum 18GB VRAM istiyor. Eğer ki VRAM bundan küçükse taşan veri RAM'e aktarılıyor ve hız ciddi manada düşüyor.
SWE Bench (AI açıklama)
Klasik "şu fonksiyonu yaz" testlerinden çok daha farklı ve dişli bir sınav bu.
Kısaca çalışma mantığı şöyle:
Gerçek GitHub Sorunları: Modellere öyle uydurma sorular değil, Django, scikit-learn veya Flask gibi devasa açık kaynak projelerindeki gerçek hata raporları (issue) veriliyor.
Uçtan Uca Çözüm Beklentisi: Modelin sadece kod parçası üretmesi yetmiyor. Mevcut binlerce satırlık kod tabanını taraması, hatanın tam yerini tespit etmesi, çözümü uygulaması ve üzerine bir de testlerini yazması gerekiyor. Yani tam anlamıyla bir yazılım mühendisi gibi davranması bekleniyor.